캐글의 타이타닉 데이터셋으로 첫 머신러닝 분석 실습을 진행했다.
데이터 전처리 과정 부터 분석 모델 평가까지 진행해 보자

➡️ 1. 데이터 LOAD & EDA
- 목표 : 로지스틱 회귀 분석으로 승객의 타이타닉호 생존유무 와 모델의 정확도 측정
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
#데이터 확인
display(train_df.shape)
display(test_df.shape)
#EDA - 데이터 분포 및 이상치 확인
train_df.info()
train_df.describe(include='all')
train_df.duplicated().sum()- 결과 : 전처리 필요한 컬럼 및 내용 확인
- 결측치 처리 :age ,cabin 해야하네
- 이상치 처리 : fare 최대값이 이상하네? 확인
- 중복값 처리 : 없음 (train_df.duplicated().sum() 무)
- 범주형 인코딩 :sex,embarked
- 수치형 데이터 스케일링
- 기타(종속 변수 전처리) : sibsp parch => family (가구원수)로 컬럼 추가
➡️ 2. 데이터 전처리
- train df 와 test df 에 동일하게 전처리 진행해야하므로 전처리 과정은 함수화 했음
- 종속 변수 전처리 : sibsp & parch => family 컬럼
#기초 가공 : df 복제
train_df2 = train_df.copy()
#family(가구원) 컬럼 생성
def get_family(df):
df['Family'] = df['SibSp'] + df['Parch'] +1
return df
get_family(train_df2).head(3)- 수치형 변수 이상치 확인 :fare 컬럼
#숫자형 변수들의(x 값) 이상치 확인하기 : pairplot
sns.pairplot(train_df2[['Age','Fare','Family']])
# Fare 이상치 제거
def get_outlier (df):
df = df[df['Fare']<512]
return df
train_df2.shape #(891-> 888)
train_df2.describe()
- 결측치 처리 : sex,embarked 컬럼 결측치 평균 값으로 대치
- 최종적으로 test_df 에 fare 값 결측치가 있어 같이 처리 해줬음
# age,Embarked 결측치 처리
def get_non_missing(df):
Age_mean= df['Age'].mean()
Fare_mean= df['Fare'].mean() #추가 ) test_df 에서 결측치 발생했으므로 추가해줌
df['Age'] = df['Age'].fillna(Age_mean)
df['Fare'] = df['Fare'].fillna(Fare_mean)#추가 ) test_df 에서 결측치 발생했으므로 추가해줌
df['Embarked'] = df['Embarked'].fillna('S') #범주형은 최빈값으로 결측치 채워줌
return df
get_non_missing(train_df2).info()- 수치형 데이터 스케일링
- Fare 컬럼 → 표준화 진행
- Age,Family 컬럼 → 정규화 진행
# 수치형 데이터 스케일링 함수 생성
#표준화 : sd Fare
#정규화 : mm Age,Family
def get_numeric_sc(df):
from sklearn.preprocessing import MinMaxScaler,StandardScaler
#모델 생성
sd_sc = StandardScaler()
mm_sc = MinMaxScaler()
#학습
sd_sc.fit(df[['Fare']])
mm_sc.fit(df[['Age','Family']])
#적용 (컬럼 생성)
df[['Fare_sd_sc']] = sd_sc.transform(df[['Fare']])
df[['Age_mm_sc','Family_mm_sc']] = mm_sc.transform(df[['Age','Family']])
return df
get_numeric_sc(train_df2).describe(include='all')- 범주형 데이터 인코딩
- 레이블 인코딩 : Sex,Pclass컬럼
- 원-핫 인코딩 : embarked 컬럼
#범주형 데이터 인코딩
#레이블 인코딩 : Sex, pclass
# 원핫 인코딩 : embarked
def get_category(df):
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#모델 생성
le = LabelEncoder()
le2 = LabelEncoder()
oe = OneHotEncoder()
#레이블 인코딩 학습 및 적용 (라벨 인코딩 학습은 1차원 배열)
df['Sex_le'] = le.fit_transform(df['Sex'])
df['Pclass_le'] = le2.fit_transform(df['Pclass'])
#원핫 인코딩 학습 및 적용 : csr 데이터 이므로 바로 컬럼에 추가 해줄수 없고 추가 가공 필요
oe.fit_transform(df[['Embarked']])
#위 값을 변수에 저장
embarked_csr = oe.fit_transform(df[['Embarked']])
# CSR 데이터 데이터프레임으로 만들기
csr_df = pd.DataFrame(embarked_csr.toarray(), columns = oe.get_feature_names_out())
#기존 데이터에 컬럼으로 추가하기 (axis = 1) 열 단위
#주의) 인덱스 기준으로 병합되므로 기존테이블 인덱스 초기화 한번 해주고 cocnat 해야함
df = df.reset_index(drop=True)
df = pd.concat([df,csr_df],axis=1)
return df
#인코딩 테이블 저장
train_df2 = get_category(train_df2)
train_df2.head(5)➡️ 3. 데이터 모델링 (로지스틱 회귀 분석)
- 로지스틱 회귀 분석 모델 사용 : 예측하려는 생존 유무는 0 or 1 값으로 이루어진 범주형 데이터니까
- 모델 수립
def get_model(df):
from sklearn.linear_model import LogisticRegression
#모델 생성 및 학습
model_lor = LogisticRegression()
X = df[['Sex_le','Age_mm_sc','Fare_sd_sc','Family_mm_sc','Pclass_le','Embarked_C','Embarked_Q','Embarked_S']]
y_true = df['Survived'] #로지스틱 회귀는 y 값을 1차원 배열로 받음
return model_lor.fit(X,y_true)
- 모델 평가
- 정확도 : 약 80.24%
- f-score: 약 73.33%
#최종 학습 된 모델 변수 저장 : model_output
model_output = get_model(train_df2)
#예측
X = train_df2[['Sex_le','Age_mm_sc','Fare_sd_sc','Family_mm_sc','Pclass_le','Embarked_C','Embarked_Q','Embarked_S']]
y_pred = model_output.predict(X)
#평가
from sklearn.metrics import accuracy_score,f1_score
ac = accuracy_score(train_df2['Survived'],y_pred)
f1 = f1_score(train_df2['Survived'],y_pred)
print (f'정확도 : {ac}, f-score : {f1}')➡️ 4. 테스트 데이터에 모델 적용 & 예측
- test_df 에 예측 모델 적용
#test 데이터 전처리
test_df2 = get_family(test_df) # 값 합치기
test_df2 = get_non_missing(test_df) #결측치 처리
test_df2 = get_outlier (test_df) # 이상치 처리
test_df2 = get_numeric_sc(test_df) #수치형 처리
test_df2 = get_category(test_df) #범주형 인코딩
#모델의 정보도 객체에 잘 저장됨
model_output.classes_
model_output.n_features_in_
model_output.feature_names_in_
model_output.coef_
model_output.intercept_
#학습된 모델로 예측 :학습된 모델변수 - model_output
test_X = test_df2[['Sex_le','Age_mm_sc','Fare_sd_sc','Family_mm_sc','Pclass_le','Embarked_C','Embarked_Q','Embarked_S']]
y_test_pred = model_output.predict(test_X)- 예측값 파일로 저장 후 캐글 업로드
- 주의 ) 컬럼 수 맞춰줘야 제대로 업로드 됨 → index 옵션 설정
#파일 불러오기
sub_df = pd.read_csv('gender_submission.csv',index_col=0)
sub_df.head(3)
#예측값으로 변경 후 저장
sub_df['Survived'] = y_test_pred
sub_df.to_csv('result.csv',index=False)➡️ K-fold 교차검증 수행
- 교차 검증 (Cross Validation) ?
- 데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용하는 방법
- k-fold 검증
- Train Data를 K개의 하위 집합으로 나누어 모델을 학습시키고 모델을 최 적화 하는 방법 (K는 분할의 갯수)
- Split을 반복 하며 최적의 학습 모델을 찾고 test에 적용
- 데이터가 부족할 경우 유용함
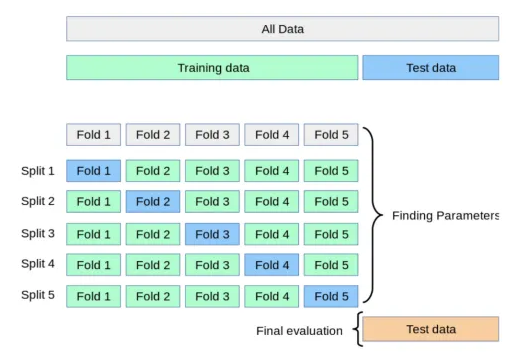
- 실습 진행한 모델의 일반화 성능을 더 잘 평가하기 위해 k-fold 교차 검증 추가 진행
from sklearn.model_selection import KFold
import numpy as np
# k fold 스플릿 갯수 설정
kfold =KFold(n_splits=5)
#스플릿의 정확도 스코어 넣어줄 배열 선언
ac_scores = []
f1_scores = []
best_pred= [] #예측값 저장
# x,y변수 할당
X= train_df2[['Sex_le','Age_mm_sc','Fare_sd_sc','Family_mm_sc','Pclass_le','Embarked_C','Embarked_Q','Embarked_S']]
y=train_df2['Survived']
#스플릿갯수 별 train& test X,y 값 생성
for i, (train_index, test_index) in enumerate(kfold.split(X)):
X_train,X_test = X.values[train_index], X.values[test_index]
y_train,y_test = y.values[train_index], y.values[test_index]
from sklearn.linear_model import LogisticRegression #모델 생성 모듈
from sklearn.metrics import accuracy_score,f1_score #적확도 평가 모듈
#모델 생성 & 학습
model_lo2 = LogisticRegression()
model_lo2.fit(X_train,y_train)
#x_test 예측
y_test_pred2 = model_lo2.predict(X_test)
#평가
accuracy = accuracy_score(y_test,y_test_pred2).round(3)
f1 = f1_score(y_test,y_test_pred2).round(3)
print(i,'번째 교차검증 정확도는',accuracy,'f1-score는',f1)
ac_scores.append(accuracy)
f1_scores.append(f1)
best_pred.append(y_test_pred2)
print('---')
print(f'평균 정확도 : {np.mean(ac_scores)} 평균 f1-scores: {np.mean(f1_scores)}')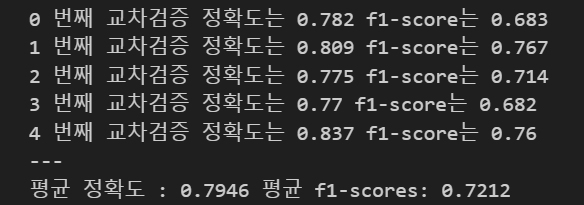
Titanic | Novice
Kaggle profile for Titanic
www.kaggle.com
'통계,검정,머신러닝' 카테고리의 다른 글
| 통계 실습2 | 카이제곱 검정 /분포별 난수로 샘플 생성하기 / 중심극한정리 (+subplots/subplot 시각화) (0) | 2025.01.18 |
|---|---|
| 통계 실습 | 변동계수 / 신뢰구간 / 이표본 t 검정 (양측검정,단측검정,정규성검정,등분산검정) (0) | 2025.01.17 |
| 머신러닝 | 이상치/ 결측치/ 범주형 데이터 인코딩/ 수치형 데이터 스케일링(+sklearn 모듈) (0) | 2025.01.15 |
| 가설 검정 | 카이 제곱 검정 (+ scipy.stats 모듈 ) (0) | 2025.01.14 |
| 통계 기초 | 오류의 종류와 오류 보정법(+본페르니 보정 코드 ) (1) | 2025.01.14 |