#simpleimputer 를 이용한 대치
from sklearn.impute import SimpleImputer
#모델 생성
si = SimpleImputer()
#학습
si.fit(data[['Age']]) #2차원 배열로 받음
#대체값 확인 : 디폴트는 평균 값
si.statistics_
#학습결과로 파악한 적절한 값을(평균 or 중앙값 등..) 행단위로 채워줌 : transform
data['Age_si_mean'] = si.transform(data[['Age']])
data.info()
#범주형 - 원핫인코딩
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#모델 생성
oe = OneHotEncoder()
#학습
oe.fit(data[['Embarked']])
#카테고리 확인 -> 4개 ->컬럼이 4개 생성 됨.
oe.categories_
#정수형으로 저장 -> 대부분의 값이 0이라 아래 코드 추가하여 추가가공 필요
oe.transform(data[['Embarked']])
정수형으로 저장시 , 대부분의 값이 0 언더 → 추가 가공 진행
#추가 가공 필요
#변수로 할당
embarked_csr =oe.transform(data[['Embarked']])
# CSR 데이터 데이터프레임으로 만들기
csr_df = pd.DataFrame(embarked_csr.toarray(), columns = oe.get_feature_names_out())
#데이터 확인
csr_df.head(3)
#기존 데이터에 컬럼으로 추가하기 (axis = 1) 열 단위
pd.concat([data,csr_df],axis=1)
➡️ 수치형 데이터 처리 ( Scaling)
목표 : 단위 값이 서로 다른 데이터들을 보정
표준화(standardization) `z-score`
각 데이터에 평균을 빼고 표준편차를 나누어 → 평균을 0 표준편차를 1로 조정하는 방법
수식 : z-score로 표준화
정규화(Normalization) `MinMaxScaler`
각 데이터를 0과 1사이 값으로 조정(최소값 0, 최대값 1)
수식 : 최소값/최대값-최소값
로버스트 스케일링(Robust Scaling) `RobustScaler`
중앙값과 IQR을 사용하여 스케일링.
수식 : 표준화에서 mean 대신 중앙값, 표준편차 대신 iqr 사용
[스케일링법 비교]
📌표준화 특징 장 : 이상치가 있거나 분포가 치우쳐져 있을 때 유용. / 많은 알고리즘에서 좋은 성능을 보임 단: 데이터의 최소-최대 값이 정해지지 않음.
📌 정규화 특징 장: 모든 특성의 스케일을 동일하게 맞춤 / 최대-최소 범위가 명확 단: 이상치에 영향을 많이 받을 수 있음(반대로 말하면 이상치가 없을 때 유용) → 왜? 최대 최소값안에 이상치가 포함되니까 데이터 분포가 매우 불균형/비대칭 할수 있음
📌로버스트 스케일링특징 장: 이상치의 영향에 덜 민감 단: 표준화와 정규화에 비해 덜 사용됨
# Fare 변수: standardScaler (표준화) 스케일링 진행
from sklearn.preprocessing import StandardScaler
#모델 생성
sd_sc = StandardScaler()
#학습 및 적용
sd_sc.fit_transform((data[['Fare']]))
#스케일링한 값 컬럼으로 저장(변수 할당 )
data['Fare_sd_sc'] = sd_sc.fit_transform((data[['Fare']]))
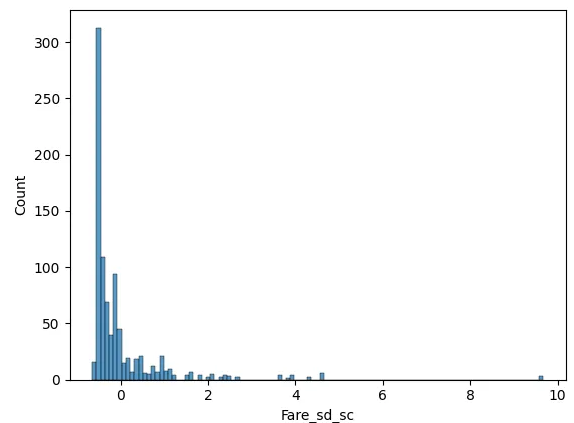
sns.histplot(data=data,x='Fare_sd_sc')
# Age_mean 변수: minmaxscaler (정규화)) 스케일링 진행
from sklearn.preprocessing import MinMaxScaler
#모델 생성
mn_sc = MinMaxScaler()
#학습 및 적용
mn_sc.fit_transform((data[['Age_mean']]))
#스케일링한 값 컬럼으로 저장(변수 할당 )
data['Age_mean_mn_sc'] = mn_sc.fit_transform((data[['Age_mean']]))
data.head(5)
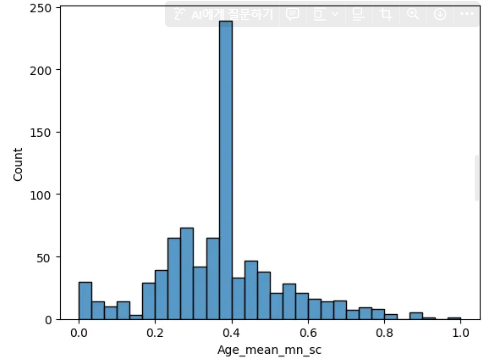
sns.histplot(data=data,x='Age_mean_mn_sc')