📂파이썬이란?
- 귀도 반 로섬이 개발한 프로그래밍 언어로 간결하고 가독성이 높은 것이 특징
- 한 줄씩 실행 가능
- 여러가지 패키지 제공
- 디버깅(debugging) : 에러를 잡는 것
Numpy: 다차원 행렬 등..
Pandas : 데이터 분석
Matplotilb / seaborn : 시각화
Scikitlearn : 머신러닝
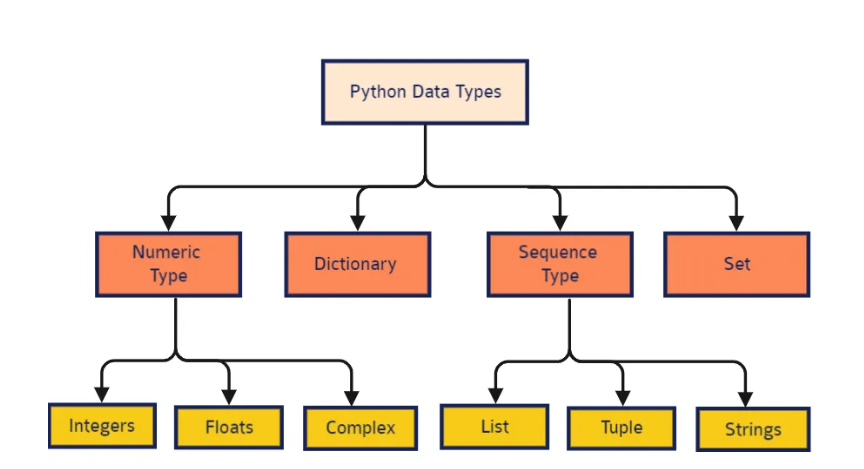
📂파이썬 자료형
- Numeric type : integers / floats
- Sequence type : string / list / tuple (순서대로 값을 담은 자료형. 인덱스 있음 )
- Dictionary
📂문자형 (String)
- `' '` 혹은 `" "` 안에 작성 ( 따옴표, 작은따옴표 자체가 문자열에 포함될때 골라서 사용해줌)
- 논리 연산식 boolean : true / false 로 나타낼 수 있는 조건 문
print("cookie's notion") #문자열 출력
- 문자열은 인덱스 있음 ( slicing / indexing 가능)
- 문자열 메소드(method) : `upper` / `lower` / `count` / `replace` / `find`
# 1. 대소문자로 변경하는 메소드 : upper(), lower()
letter ='how are YOU'
print(letter.lower()) # how are you 출력
# 2. 값 카운팅 메소드 : count(값)
letter ='how are YOU'
print(letter.count('how')) # 1 출력
# 3. 값 변경 메소드 : replace(a,b) a를 b로 변경
letter ='how are YOU'
print(letter.replace('you','you doing?')) # how are you doing? 출력
# 4. 인덱스 찾아주는 메소드 : find(a) a의 인덱스 반환
letter ='how are YOU'
print(letter.find('h')) # 0 출력📂리스트 (List)
- 데이터를 담고, 정리하고, 불러올 때 사용
- 기본형 : [A,B,C,D...]
- 순서가 있는 자료형 ( 인덱스 있음)
- 인덱싱 (Indexing) : 특정 `자료에` 접근 `a_list [ n ]`
- 인덱싱은 0부터 시작, 맨 마지막 부터는 -1부터 시작
- 슬라이싱 (slicing) : 자료의 `범위`에 접근 `a_list [ a: b]`
- a는 시작점(start index). 앞에서부터 0, 뒤에서 부터 -1 로 시작.
- b는 끝점(end index) : 슬라이싱 시, 끝 값 직전까지만 포함됨 = 끝값은 포함 안됌됨.
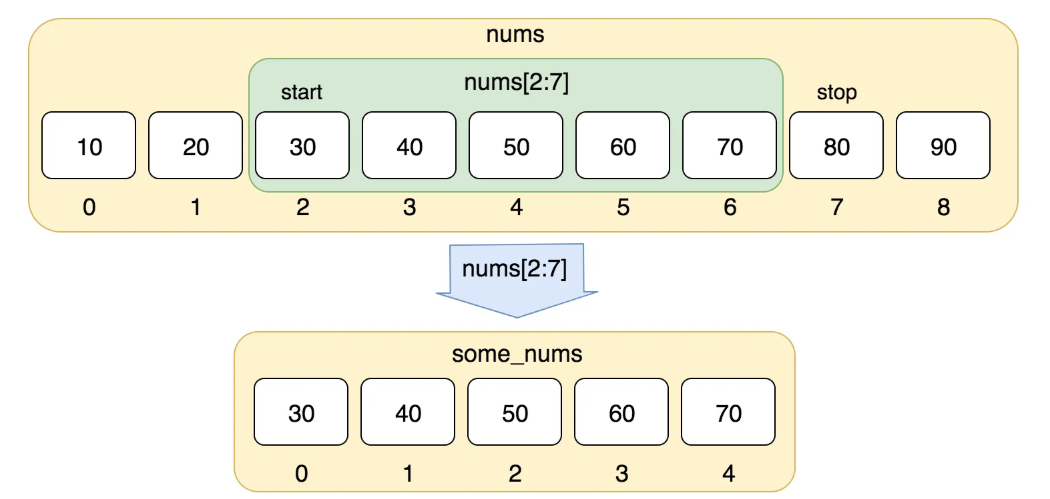
# 형태: new_list = old_list[start:end:step]
a = [1, 3, 2, 4]
print(a[3]) # 4
# 슬라이싱
print(a[1:3]) # [3, 2]
#마이너스 슬라이싱
print(a[-1]) # 4 (맨 마지막 것 : 뒤에서 부터 -1~ )
print(a[-2:]) # [2,4] (맨 마지막 것 : 뒤에서 부터 -1,-2 ... )
# 주의)) 뒤에서부터 인덱스의 슬라이싱은 역순이 아닌 시작점만 의미
print(a[-3:-1] #[3,2] 출력 -1인덱스 직전까지 출력되니까 2개
# 디벨롭1. 특정 간격으로 추출하기
b=[1,2,3,4,5,6,7,8,9,10]
print(b[1:9:2]) # 인덱스 1부터9 직전까지(index 1-8까지) 불러올껀데 2개씩 건너 뛰면서 [2,4,6,8]
# 디벨롭2. 리스트 거꾸로 뒤집기
reversed_list = my_list[::-1] #시작부터 끝까진데, -1순으로
print(reversed_list) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] 출력
print(my_list[::-2]) #[10, 8, 6, 4, 2] -2씩 건너뛰며 출력
- 리스트 메소드 (Method) : `append` `insert` `remove` `pop` `sort`
#1-1 리스트에 항목 추가하기 : append(a)
a = [1, 2, 3]
a.append(5)
print(a) # [1, 2, 3, 5]
#1-2 특정 위치에 값 추가하기 : insert(a,b)
my_list.insert(2, 10) # 인덱스2에 10값 삽입
print(my_list) # 출력: [1, 2, `10`, 3, 4, 5, 6, 7, 8, 9]
#2-1 리스트에 항목 삭제하기 :del
del my_list[0]
print("첫 번째 항목 삭제 후 리스트:", my_list)
#2-2 리스트에 특정 값 삭제하기 : remove(삭제할 값) / pop(삭제할 인덱스)
my_list.remove(3) # 값 3 삭제
print(my_list) # 출력: [1, 2, 10, 4, 5, 6, 7, 8, 9]
popped_value = my_list.pop(5) # 5번째 위치의 값 제거하고 반환
print(popped_value) # 출력: 6
print(my_list) # 출력: [1, 2, 10, 4, 5, 7, 8, 9]
#3-1 리스트 정렬 (오름차) :sort()
my_list.sort()
print(my_list) # 출력: [1, 2, 4, 5, 7, 8, 9, 10]
#3-2 리스트 정렬 (내림차) : sort(reverse=true)
my_list.sort(reverse=true)
print(my_list) # 출력: [1, 2, 4, 5, 7, 8, 9, 10]
#3-3 리스트 역순으로 정렬 : reverse
my_list.reverse() # 리스트 역순으로 뒤집기
print(my_list) # 출력: [10, 9, 8, 7, 5, 4, 2, 1]📂튜플 (Tuple)
- 불변형 리스트 (immutable) : 리스트와 동일하게 순서는 존재 하지만, 리스트 값을 삽입/삭제/변경 이 불가하다.
- 기본형 : (A,B,C,D...)
my_tuple = (1, 2, 3, 'hello', 'world')
my_tuple = 1, 2, 3, 'hello', 'world' # 동일
- 튜플 메서드(Method) : `count` `index`
my_tuple = (1, 2, 3, 4, 1, 2, 3)
# count() 메서드 예제 : 값이 몇개인지 반환
count_of_1 = my_tuple.count(1) # 1이 몇개냐
print("Count of 1:", count_of_1) # 출력: 2
# index() 메서드 예제 :값이 있는 인덱스 반환
index_of_3 = my_tuple.index(3) #3은 몇번째? 1번째에 있는 인덱스 반환
print("Index of 3:", index_of_3) # 출력: 2
- 튜플 합치기/연결하기/반복하기 : 연산자
tuple1 = (1, 2, 3)
tuple2 = ('a', 'b', 'c')
new_tuple = tuple1 + tuple2 # 두 개의 튜플을 합치기
print(new_tuple) #(1,2,3,'a','b','c') 출력
repeated_tuple = tuple1 * 3 # 튜플을 반복하기
print(repeated_tuple) #(1, 2, 3,1,2,3,1,2,3) 출력
my_tuple = (1, 2, 3, 4, 5) # 튜플←→리스트 변환
my_list = list(my_tuple) #my_tuple =tuple(my_list)
print(my_list) # 출력: [1, 2, 3, 4, 5]📂딕셔너리 (Dictionary)
- 딕셔너리는 키(key)와 밸류(value)의 쌍으로 이루어진 자료의 모임
- 기본형 : {키:값,키:값,키:값...]
- key는 고유값이므로 중복 불가 / 딕셔너리는 순서 없음(인덱스 불가)
- 표 만들기 용이
person = {"name":"Bob", "age": 21}
#1.딕셔너리 쌍 출력
print(person) #{"name":"Bob", "age": 21} 출력
#2.딕셔너리 값 출력 : 변수[”키”] ⇒ '값' 출력
print(person["name"])
#3. 빈 딕셔너리 만들기
a = {}
a = dict()
#값 추가/삭제/수정
person = {"name":"Bob", "age": 21}
# 수정
person["name"] = "Robert"
print(person) # {'name': 'Robert', 'age': 21}
#추가
person["height"] = 174.8
print(person) # {'name': 'Robert', 'age': 21, 'height': 174.8}
#삭제
del person["name"]
print(person) # {'age': 21, 'height': 174.8}
- 딕셔너리 메소드(method) : `keys` `values` `items`
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# keys() : 키값 반환
keys = my_dict.keys()
print("Keys:", keys) # 출력: dict_keys(['name', 'age', 'city'])
# values() 값 반환
values = my_dict.values()
print("Values:", values) # 출력: dict_values(['John', 30, 'New York'])
# items() 딕셔너리의 값을 쌍으로 전달
items = my_dict.items()
print("Items:", items) # 출력: dict_items([('name', 'John'), ('age', 30), ('city', 'New York')])
- 강의 퀴즈
my_list = [10, 20, 30, 40, 50]
#3번째 요소 출력하기
my_list[2]
#리스트에 60 추가하기
my_list.append(60)
my_list
#리스트의 길이 출력
print(len(my_list))
my_list2 = ['car', 'bus', 'bike', 'train']
#마지막 요소 제거 -값(remove)
my_list2.remove('train')
my_list2
#마지막 요소 제거 -인덱스 (pop)
my_list2.pop[2] # 디벨롭 만약 마지막 값의 키를 모를때는? : my_list2.pop[-1]
my_list2
my_list3 = ['red', 'green', 'blue', 'yellow']
#리스트 역순 출력
my_list3.reverse() # my_list[::-1] 도 가능. 처음부터 끝까지 반대로 출력
my_list3my_tuple = (10, 20, 30, 40, 50)
#1 다음 튜플에서 세 번째 요소를 출력하세요.
my_tuple[2]
my_tuple = ('apple', 'banana', 'orange', 'grape')
#2 다음 튜플의 길이를 출력하세요.
print(len(my_tuple))
my_tuple = ('red', 'green', 'blue', 'yellow')
#3 다음 튜플을 역순으로 출력하세요. - 리스트로 변환후 리버스 메소드 & 다시 튜플로
a_list=list(my_tuple)
a_list.reverse()
my_tuple2 = tuple(a_list)
my_tuple2
#3-1 역순 출력 : 인덱스 사용
my_tuple = ('red', 'green', 'blue', 'yellow')
re_tuple = my_tuple[::-1]
my_tuple = (1, 2, 3, 4, 5)
#4 다음 튜플을 리스트로 변환하세요.
my_list =list(my_tuple)
my_list
#5 다음 튜플과 다른 튜플을 연결하여 새로운 튜플을 만드세요.
my_tuple1 = ('a', 'b', 'c')
my_tuple2 = ('d', 'e', 'f')
my_tuple1 + my_tuple2# 1다음 딕셔너리에서 'name'에 해당하는 값을 출력하세요.
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
my_dict['name'] # or 메서드 사용가능
#2 다음 딕셔너리에 'gender'를 추가하세요.
my_dict = {'name': 'Bob', 'age': 25, 'city': 'Los Angeles'}
my_dict['gender'] = 'woman'
my_dict
#3 다음 딕셔너리의 길이를 출력하세요.
my_dict = {'a': 100, 'b': 200, 'c': 300}
print(len(my_dict)) #3쌍
#4 다음 딕셔너리에서 'age'를 제거하세요.
my_dict = {'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
del my_dict['age']
my_dict🔥딕셔너리 효율성 & 리스트의 시간 복잡도🔥
- 딕셔너리는 성능면에서 리스트 보다 좋음
1. `왜?` 리스트는 삽입/삭제시 인덱스를 하나씩 다 밀어야함.
2. 데이터 갯수 만큼 (n)의 속도가 걸림
3. [0] 번째 인덱스에 값 삽입시 시간이 가장 오래걸림 = 시간 복잡도 - 딕셔너리는 어떤 값을 넣든 반드시 일정한 소요시간이 걸림
`왜?` 데이터를 찾고 넣는 시간에 리스트처럼 하나씩 자료형을 미는게 아닌 해쉬 함수(Hash Fucntion) 로 접근하기 때문.
파이썬 | 변수 / 문자열 / 슬라이싱 / List / Dictionary
📂 변수- Python에서는 변수에 값을 저장하여 출력할 수 있음 ( 파이썬은 사실 변수의 값이 저장된 메모리 위치를 출력하는 하는 것 )- 변수는 자료형, 숫자형 등 모든 형태 지정이 가능함name = "
cookievlog.tistory.com
'PYTHON' 카테고리의 다른 글
| 파이썬 | 함수(def)와 변수, 인수, 매개변수 (1) | 2024.12.11 |
|---|---|
| 파이썬 | 조건문 if / 반복문 for & while 2 (1) | 2024.12.11 |
| UDEMY | 100DAYS OF CODE - day1 (0) | 2024.12.02 |
| 파이썬 실습 | 키오스크 코드 작성3 (2가지 조건하에 값 출력 &f-string&형 변환 ) (0) | 2024.11.28 |
| 파이썬 | RANGE/FOR ~RANGE 증감폭/ RANGE 실습 (0) | 2024.11.28 |