1. 분석 개요
☑️ 분석 목적
Starbucks Customer Data
Starbucks customer dataset
www.kaggle.com
- Kaggle 에서 제공되는 'Starbucks Customer Data' 의 고객/ 프로모션/고객 행동 테이블을 사용하여 프로모션 성과 분석 및 고객 segmentation 연습
- Python의 pandas , matplotlib,seaborn 등의 라이브러리를 활용하여 데이터 전처리 및 시각화 진행
- 여러개의 테이블 간의 구조와 관계 파악 (ERD 도식화)
☑️ 분석 목표
- 프로모션 성과 분석을 통한 프로모션 타겟 고객 점검 및 개선 방안 제안
- 인구통계, 고객 행동 기반으로 segmentation 진행
☑️ 분석 기간
- 24/12/26~24/1/2 (6일)
2. 테이블 설명
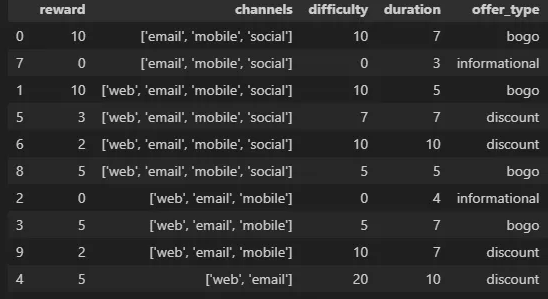
☑️ Portfolio : `프로모션 정보 테이블`
- 행/열 : (10,6)
- 결측치 & 중복값 없음
- 컬럼 확인
- reward :프로모션 혜택 / 할인 금액
- difficulty : 프로모션 참여에 필요한 금액 / 최소 결제 금액 `예: 2$ Discount Promotion을 위해서 10$ 써야함`
- duration :프로모션 혜택 적용 기간 (유효 기간)
- offer_type :3가지 타입(bogo,discount,informational)
- channels :4가지 옵션으로 구성 (단일 채널 유입 여부는 모름)
- 이메일 모바일 소셜 웹
- 이메일,모바일,소셜
- 이메일 모바일 웹
- 이메일 웹
☑️ Profile : ` 고객 인구 통계학 정보 테이블 `
- 행/열 : (17000,5) ⇒ 17,000명의 고객 정보 (결측치 제거시 → 최종 : 14,825 명)
- 결측 치 : gender / income 컬럼에 2,175개 존재 (약 12%)
- 중복 값 :없음
- 컬럼 이해
- id : 고객 식별 id
- `transcript` 테이블의 고유 고객수랑 일치 함 : `profile 데이터는 프로모션 기간내 이벤트가 발생한 고객 정보만 추출했을 가능성 이 큼`
- 즉, 활성 고객만 추출
- income : 고객 소득 ( min 3만달러, max 12만 달러)
- became_member_on : 앱 계정 가입한 고객 정보임 (가입일자)
- 이벤트 결과내 가장 오래된 유저 2013-07-13 가입, 가장 최근 유저 2018-07-26 가입
- age : 고객 나이 (min 18~ max 118 세)
- 이상치 처리 : 나이 118 제거 필요
- id : 고객 식별 id

☑️ Transcript : ` 고객 행동 로그 테이블 `
- 행/열 : (306534, 4 )
- 결측치 : 없음
- 중복 값 : 397개 →전처리 진행후 : 30,6137 행
- 컬럼 이해
- person (고객 id) : 고유 값 : 17,000 명
- event (이벤트 유형) : 4단계 오퍼 받음, 봄, 완료, 거래
- value( 프로모션 정보 ): 3유형( offer id, reward, amount) 이 json 타입으로 저장
- 전처리 필요
- value 값중 offer id 이 portfolio 의 id와 연결됨 (join key)
- time(첫 프로모션 시작일 기준 걸린 시간)
- 첫 프로모션 발송 후 6시간 단위로 한달간 데이터 저장 ( min 0- max714 )
- 값이 날짜가 아니라 0- 714 int로 저장되어 있기 때문에, 전체 테이블 컬럼 중 `time` 컬럼이 정확하게 어떤 의미인지 파악하기 어려웠다.
- 예컨데, 모든 고객이 수신한 첫번째 프로모션을 기준으로 714시간 동안 고객 로그를 담은 데이터 인지(고객 기준) or 프로모션 시작 시점 기준 714시간 동안 고객 로그를 담은 데이터 인지 헷갈렸다.(프로모션 기준)
- 🔑 결론적으로 고객의 첫 `time`은 0 이 아닌 다양한 값을 가질 수 있고
- 🔑 프로모션 타입별 고객의 오퍼 수신(=오퍼 발송) 시각이 동일한 시각과 주기로 발생 하는점을 미루어
- 🔑 transcript 테이블은 `프로모션 발송(=오퍼 수신) 기준 714시간 동안의 고객행동 로그가 저장되어 있는 테이블` 이라고 추정할수있을것 같다.
- 첫 프로모션 발송 후 6시간 단위로 한달간 데이터 저장 ( min 0- max714 )
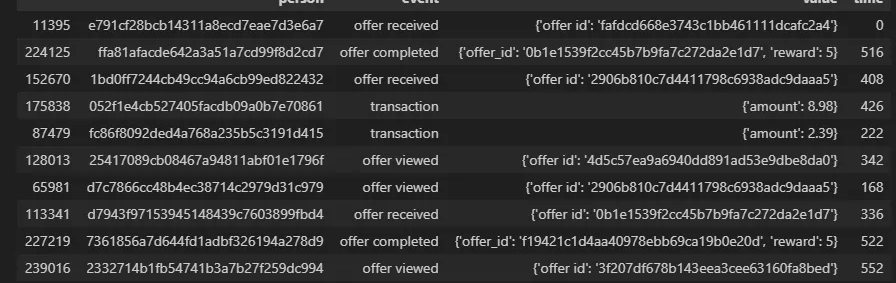
#고객의 첫 time 고유값 확인하기
pro_trans.sort_values(by='time')
pro_trans.groupby('person')['time'].first().unique()
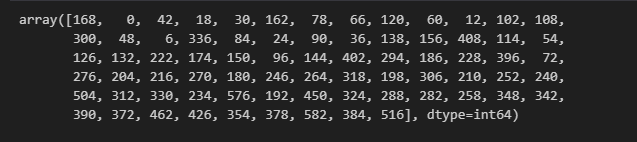
# 프로모션 오퍼한 첫 시각 확인 => 즉, 각 프로모션은 동시에 시작해서 동시에 끝남 0일 - 24일
recieved_events = pro_trans[pro_trans['event'] == 'offer received']
#프로모션별 오퍼 시작 시각 확인
recieved_events.groupby('value_offer_id')['time'].unique()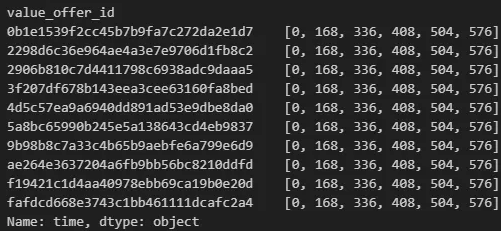
🔑time 컬럼 추가 해석 내용++
- 팀원들과 같이 eda 하는 과정에서 `time`이 절대적인 시각이냐 아니냐에 대한 이야기를 나눴다 (추후 RFM 에서 `recency` 기준으로 사용할 수있을지 대한 논의 과정에서)
- 위에서 eda 한 결과, time은 프로모션 발송 기준 경과한 시간 이라는 걸 알았고, 여기서 나는 위에10개의 프로모션이 발생한 시각이 동일하다고(절대적인 날짜) 해석했다. (예컨데, time=0 은 2018-01-01, time=168 은 2018-01-08 ) 하지만 계속 의문이 들었던 점이, 그렇다면 왜 '날짜'로 안하고 굳이 '숫자(경과 시간)' 으로 값을 저장 했을까에 대한 부분이었다.
- 다른 팀원의 해석으로는, 프로모션 발송 시각이 다 다를 수도 있다는 의견이 있었다. 예컨데, 1번 오퍼 종료 이후 2번 오퍼를 발송한 경우, time=0 이더라도 더 최신 날짜에 해당. 만약 동일한 시각(time)에 여러 오퍼를 받는 경우가 있었다면, 현실적으로 한 사람이 여러 프로모션을 동시에 받진 않으므로 발송시각은 다 다르다는 의견에 더 힘을 싣을수있을것 같다. 하지만, 확인결과 동일 시각엔 한가지 오퍼만 받으므로 이것도 확실친 않다.
- 결론은, time에 대한 해석은 2가지로 추정해 볼수있다 . 1.프로모션 발송 시점은 특정일로 동일 2.프로모션 발송 시점은 각기 다름
회고
더보기
1차 프로젝트 진행때도 느꼈던 건데, 주어진 데이터셋을 분석할때 (캐글 데이터같은)는 추출된 데이터를 누가 / 어떤의도와 목적을 가지고 추출했는지가 하나의 힌트가 되는것 같다.예컨데, 이번에 진행하고 있는 스타벅스 데이터의 경우 '프로모션 성과를 분석' 하여 더 효과적으로 프로모션을 진행하기 위해 추출된 데이터이다. (물론 해당 데이터는 실제와 유사한 가상의 데이터다) 따라서, 추출한 담당자는 마케터일 확률이 높고, 해당 데이터는 자신이 기획한 프로모션 성과를 분석하거나 앞으로 기획할 프로모션에 적용하기 위해 추출한 데이터 일것이다. 내가 그 담당자라고 생각하고 그의 의도를 생각하면서 데이터에 접근하니까, EDA 진행할 때도 흐름에 맞춰서 적당히 필요한 부분만 할수있었던 것 같다.
결론은 뭐든 의도와 목적이 중요하다. 회사다닐 때, 전임자가 기획한 상품의 의도를 알수없어 상품 분석이 어려웠던 기억이난다. 의도와 목적을 모르면 엉뚱한 결과를 도출 할 수 있고, 비용 손실도 크다. 이런 습관 때문에 자연스럽게 생각이 이렇게 흘러간 걸지도..
어쨋든 내일은 유의미한 결과가 도출되는 분석을 해보자.,.
결론은 뭐든 의도와 목적이 중요하다. 회사다닐 때, 전임자가 기획한 상품의 의도를 알수없어 상품 분석이 어려웠던 기억이난다. 의도와 목적을 모르면 엉뚱한 결과를 도출 할 수 있고, 비용 손실도 크다. 이런 습관 때문에 자연스럽게 생각이 이렇게 흘러간 걸지도..
어쨋든 내일은 유의미한 결과가 도출되는 분석을 해보자.,.

'PYTHON' 카테고리의 다른 글
| 프로젝트 회고 | Kaggle 스타벅스 마케팅 데이터 분석 : 데이터 EDA (0) | 2025.01.05 |
|---|---|
| 프로젝트 회고 | Kaggle 스타벅스 마케팅 데이터 분석 : 데이터 전처리 (0) | 2024.12.31 |
| 실습 | PANDAS 누락 기간 생성 / 조건별 증감율 계산하기( date_range/reindex/apply) (1) | 2024.12.26 |
| 실습 | PANDAS 결측값 및 IQR 기준 이상치 처리하기(dropna/drop /quantile/str.contains/apply/isdigit) (0) | 2024.12.26 |
| 실습 | PANDAS 삼성전자 종가 데이터 전월비 증감율 구하기 (strftime / pct_change/shift) (1) | 2024.12.26 |