☑️ 문제1. 데이터 조회, 정렬, 조건 필터
[문제]
- 타이타닉 데이터에서 아래 조건을 만족하는 코드 작성
- 나이가 20살 이상 40살 미만인 승객
- pclass가 1등급 혹은 2등급인 승객
- 열(column)은 survived, pclass, age, fare 만 나오게 출력
- 10개만 출력
[문제 풀이]
정답 코드
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
# df.info()
# 다중 조건 변수에 할당
condition = (df['age']>=20) & (df['age']<40) & (df['pclass'].isin([1,2]))
# 인덱스 정렬 후 10개만 출력
df.loc[condition,['survived','pclass','age','fare']].head(10).reset_index()
단계적 설명
- 다중 조건 필터링
- age 20이상, age 40미만, pclass 가 1과 2 일때 조건을 df에서 불리안 값으로 대치
- 간단한 출력을 위해 변수에 할당
- isin 메소드 외 (df['pclass']==1 | df['pclass']==2) 도 가능
- 필터링 된 조건 행 & 출력 컬럼 출력: `loc()` 메소드
- 위에서 부터 10개 출력 : `head()` 메소드
- 인덱스 초기화 : `reset_index()`
▼ `reset_index()`
더보기

reset_index(drop =False)
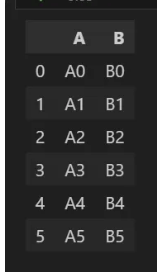
reset_index(drop=True)
- 인덱스 초기화 해주는 메소드.
- 파라미터 옵션 : drop= True 시 기존 인덱스 제거 후 정수형으로 반환 (drop = False 디폴트, 기존 인덱스는 컬럼화)
- 파라미터 옵션 : inplace= True 시 원본 데이터 수정
[KEY POINT & TIP]
🔑 pandas 에서 행 필터링 후 원하는 컬럼만 출력 할 경우, loc 메소드로 접근
df. loc [필터링후 불리안타입의 df (행취급) ,'컬럼1'(열) ]
🔑필터링 후 인덱스 정렬/초기화 해주는 메소드 : reset_index()
☑️ 문제2. 데이터 합치기 및 컬럼 생성
[문제]
- 고객데이터와 주문 데이터를 합치고 주문여부에 따라 고객 분류 하는 코드 작성
- 고객 테이블(customers)를 기준으로 주문 테이블(orders)를 합쳐주세요. 주문 금액이 없는 고객도 모두 포함되어야 합니다.
- 주문 금액이 없는 경우, 0으로 표현하세요.
- 주문금액이 있는 경우 "구매", 주문금액이 0인 경우 "미구매"로 분류하는 "구매여부" 칼럼을 생성하세요.
- df출력 (결과칼럼: 고객번호, 이름, 금액, 구매여부)
[문제 풀이]
정답 코드
.import pandas as pd
import numpy as np
#고객 테이블
customers = pd.DataFrame({
'고객번호': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'이름': ['승철', '동경', '예나', '혜연', '장훈', '채운', '다연']
})
#주문 테이블
orders = pd.DataFrame({
'cno': [1001, 1001, 1005, 1006, 1008, 1001],
'금액': [10000, 20000, 15000, 5000, 100000, 30000]
})
# join key 이름 변경 & merge & 타입 변경
orders.rename(columns={'cno' : '고객번호'},inplace=True)
merge_df = pd.merge(customers,orders,on='고객번호',how='left')
#주문 금액이 없는 경우 null -> 0 대체
merge_df['금액'].fillna(0,inplace=True)
merge_df['금액'] = merge_df['금액'].astype('int') # 기본 float 타입, int 타입으로 변경하여 소수점 날리기
#구매여부 컬럼 추가 생성 (주문금액 0 이면 미구매, 0이 아니면 구매)
merge_df['구매여부'] = '구매'
merge_df.loc[merge_df['금액']==0,'구매여부'] = '미구매'
merge_df
단계적 설명
- 조인키 이름 일치 & df 병합
- customers & orders 의 조인키는 고객번호,cno 로 컬럼명 일치시켜줌 : `rename`
- 주문금액이 없는 고객도 포함이므로 `merge` 메소드의 how 파라미터 옵션 `left` 로 테이블 연결
- 컬럼명 일치 안시켜줄 경우, merge 파라미터에서 left_on= ,& right_on= 사용 후 drop 으로 중복 컬럼 제거 해줘야함.
- 주문금액이 없는 (null)인 경우 0으로 대치 : `fillna()`
- fillna('대체값')
- 원본 테이블에 바로 수정이 필요한 경우, inplace=True 옵션 활용
- 구매여부 컬럼 생성 및 조건별 구매/ 미구매 값 저장
- '구매' 값으로 저장된 '구매여부'컬럼 생성
- loc 로 '금액'이 0 일때, '구매여부' 컬럼에 '미구매' 값 저장(변경)
- np.where 메소드 활용하여 np.where ( 조건식,'참 값','거짓값') 으로 컬럼 값 변경 할 수 있음
# 컬럼명 일치 안 시킨 후 병합하기
df = pd.merge(customers, orders, left_on = "고객번호", right_on = "cno", how = "left")
df.drop(columns = "cno", inplace = True)
# numpy 로 조건별 값 저장하기
df["구매여부"] = np.where(df["금액"] > 0, "구매", "미구매")[KEY POINT & TIP]
🔑두개의 df merge 할때, 조인키 이름 선 일치 하는게 낫다 ( drop 코드 안쓸수있음)
🔑 조건별 컬럼값 저장/변경 시, np.where 메소드 활용하면 더 빠르고 간단함
'PYTHON' 카테고리의 다른 글
| 실습 | PANDAS 삼성전자 종가 데이터 전월비 증감율 구하기 (strftime / pct_change/shift) (1) | 2024.12.26 |
|---|---|
| 실습 | PANDAS 집계 함수/ 상관관계 / 산점도 그리기 ( agg/corr/ matplotlib vs seaborn) (0) | 2024.12.26 |
| 웹 크롤링 | 파이썬으로 동적 페이지 간단하게 크롤링 하기 ( Selenium / 무신사 웹 크롤링 실습 코드) (0) | 2024.12.23 |
| 데이터 시각화 | Matplotlib 기본 그래프 ( bar / hist / pie / boxplot / scatter ) (0) | 2024.12.20 |
| 데이터 시각화 | Matplotlib 기본 of 기본 문법 (1) | 2024.12.19 |