☑️결측치 확인 및 제거 하기
[문제]
- user_purchase_data.csv 파일에는 결측치가 포함되어 있습니다. 모든 결측치를 확인하고, 결측치가 있는 행을 제거하세요.
[문제 해결]
▼ 결측치 (null 값) 메소드 `isna` `isnull` `dropna`
더보기
- 결측치 확인: `isna()` ,`isnull()`
- boolean 으로 출력 됨 → null 이면 True ,아니면 False
- df['컬럼'].isna() : 특정 컬럼의 null값 도 확인 가능
- 결측치 갯수 파악 : `isna().sum()` or `isnull().sum()`
- sum() 메소드는 불리안 형일때, True 값을 카운팅 해줌
- 결측치 제거 : `.dropna()`
#데이터 읽기
df = pd.read_csv('./user_purchase_data.csv', index_col =0)
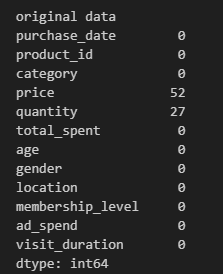
#결측치 확인
missing_data = df.isna().sum()
print(missing_data)
#결측치 제거 & 출력
cleaned_data = df.dropna()
cleaned_data☑️ 중복 데이터 확인 및 제거하기
[문제]
- 중복된 구매 데이터를 확인하고 제거하세요. 중복의 기준은 user_id, purchase_date, product_id가 동일한 행으로 합니다.
[문제 해결]
#데이터 로드
df =pd.read_csv('./user_purchase_data.csv')
# 1. 중복 데이터 확인
duplicated_cnts = df.duplicated(subset=['user_id','purchase_date', 'product_id'])
print(f'중복 데이터 갯수 : {duplicated_cnts.sum()}') # 중복 데이터 갯수 세기 (불리안 T 카운팅)
# 2. 중복 데이터 제거
cleaned_data = df.drop_duplicates(subset=['user_id','purchase_date', 'product_id'])
cleaned_cnts = cleaned_data.duplicated()
print(f'중복제거 후 데이터 갯수 : {cleaned_cnts.sum()}') #불리안 시리즈 T 카운팅
print(cleaned_data)
▼ 중복 데이터 메서드 `duplicated()` `drop_duplicates()`
더보기
- 중복 데이터 확인: df.duplicated (subset=[’컬럼’],[keep=’first’])
- return : 불리안 시리즈로 반환
- keep= ‘first’ : [디폴트 값], 중복 값 중 첫번째만 F 나머지 T
- keep= ‘last’ : 중복값 중 마지막꺼만 F 나머지 T
- keep=False : 모든 중복값이 T
- subset=[’컬럼’] : 특정 열에서 중복 찾을 때 매개변수 활용, 여러 컬럼 리스트로 묶어줌
- 중복 데이터 제거 : df.drop_duplicates (subset = ['컬럼’ ] , [keep = 'first '] ,[ inplace = False] )
- inplace : 디폴트 False (새로운 df를 생성 후 저장) True ( 기존 df 수정 저장)
- 중복 데이터 세기 : 불리안시리즈.sum()
# 중복 데이터 확인
df.duplicated(subset=['컬럼1', '컬럼2', '컬럼3'])
# 중복 데이터 제거
df.drop_duplicates(subset=['컬럼1', '컬럼2', '컬럼3'])
#갯수 세기 .sum() :불리안 T를 1로 취급
duplicated_data = df.duplicated(subset=['컬럼1', '컬럼2', '컬럼3']) #불리안시리즈로 반환
duplicated_data.sum() #True의(중복된) 갯수 출력 해줌☑️ 이상치 확인 및 제거하기 (IQR 기반)
[문제]
- price 컬럼에 이상치가 존재합니다. IQR (Interquartile Range) 방법을 사용하여 이상치를 찾아 제거하세요.
[문제 해결]
- 백 분위수 구하기 / IQR 구하기 /상*하한 이상치 구하기
- 이상치 제거 후 출력 : 정상값(iqr 범위)만 출력하기
- 행 갯수 확인 하기 : `.shape`
- .shape() : 레이블 정보를 튜플 형식으로 반환 → (rows,columns)
- df.shape[i] :튜플이므로 슬라이싱 가능
- df.shape[0] 행 갯수 , df.shape[1] 열 갯수
#이상치 확인 : quantile ( 소수점 )
q1 = df['price'].quantile(0.25)
q2 = df['price'].quantile(0.50)
q3 = df['price'].quantile(0.75)
iqr = q3-q1
upper_bound = q3 + 1.5 * iqr #상한 이상치
lower_bound = q1 - 1.5 * iqr #하한 이상치
#이상치 출력
print(f'q1 : {q1}\nq2 : {q2}\nq3 : {q3}')
print(f'upper_bound: {upper_bound}')
print(f'lower_bound: {lower_bound}')
# 이상치 제거 = 정상값 만 출력
inlier_df = df[(df['price']>=lower_bound) & (df['price']<=upper_bound)] #정상치 조건을 만족하는 df
print(inlier_df)
# 갯수 세기 (정상치 갯수/이상치 갯수)
total_cnts = df['price'].count() # 전체 행 갯수
outlier_cnts = total_cnts - inlier_df.shape[0]
print(f' 정상치 갯수 : {inlier_df.shape[0]}') # 중복값 필터링 한거에 행 갯수 세기
print(f' 이상치 갯수 : {outlier_cnts}')
▼ 이상치 (IQR) 메서드 `.quantile()`
더보기
[IQR 계산]
- Q1 = df['컬럼1'].quantile(0.25)
- Q3 = df['컬럼1'].quantile(0.75)
- IQR = Q3 - Q1
[이상치 기준 설정]
- lower_bound = Q1 - 1.5 * IQR
- upper_bound = Q3 + 1.5 * IQR
[이상치 제거 후 출력]
- df[(df['컬럼1'] >= lower_bound) & (df['컬럼1'] <= upper_bound)]
- a= df['컬럼1'] >= lower_bound) & (df['컬럼1'] <= upper_bound) : df가 하한치이상 상한치 이하 일때(True)
- df[(a] : True 인것만 출력
[이상치 갯수]
- outlier_cnts = (df['price']<lower_bound) | (df['price']>upper_bound)
- print(f' 이상치 갯수 : {outlier_cnts.sum()}') #T인 값만 sum() 세줌
☑️ MIN-MAX 정규화 (numpy / sklearn 패키지 활용)
[문제]
- total_spent 컬럼을 Min-Max 정규화를 사용하여 0과 1 사이의 값으로 변환하세요.
[문제 해결1 -numpy]
- min, max 메소드 활용하여 price values 정규화 진행
min_df = df['total_spent'].min()
max_df = df['total_spent'].max()
x = max_df - min_df
print('min-max nomalization : ')
df['nomalization'] = ( df['total_spent'] - min_df )/x #min-max 정규화한 값을 nomalization 컬럼에 추가
print(df[['total_spent','nomalization']]) #두개 컬럼 출력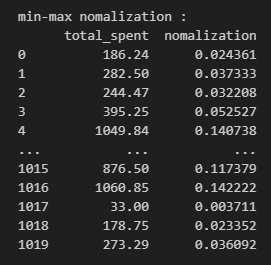
▼ min-max nomalization (MIN-MAX 정규화)
더보기

- 최대/최솟값을 이용하여 모든값들을 0-1 사이로 데이터 스케일링 (변환)
- 각기 다른 범주의 값들을 0과 1사이의 값으로 차원을 맞추는 방법
- 즉, 분포 (상대 크기) 는 유지하면서 단위를 통일하는 과정
- 결과에 대한 변수들의 영향을 정확하게 확인하기 위해 주로 사용
- 계산 : ( 값 - 최소값) / (최대값- 최소값)
[문제 해결2 -sklearn]
- scikit learn 라이브러리를 활용하여 동일한 문제를 간단하게 풀수 있음
- scikit learn 은 numpy 기반으로 만든 라이브러리임
- 사이킷런 설치 : 터미널에 `pip install scikit-learn` 실행
- 그 중 데이터 전처리 패키지 sklearn.preprocessing 의 MinMaxScaler 클래스(모듈) 가져옴
- `from sklearn.preprocessing import MinMaxScaler`
- `from 파일 import 모듈` 로 불러올 경우 sklearn.preprocessing. 생략 가능
- 클래스 객체 생성 : scaler = MinMaxScaler() → scaler 라는 객체 생성
- 데이터 학습(min~max 정규화) 및 변환 :
- scaler.fit(df) : 데이터를 학습 시키는 메서드 (min,max 를 넣어 데이터 학습)
- scaler.transform(df) : 값을 범위안으로 변환 시켜주는 메서드 (모든값들을 0-1 사이값으로 변환)
- scaler.fit_transform(df) : 학습 및 변환 한꺼번에 해주는 메서드
from sklearn.preprocessing import MinMaxScaler
# 데이터 로드
data = pd.read_csv('./user_purchase_data.csv')
# Min-Max 정규화
scaler = MinMaxScaler() # scaler 객체 생성 (클래스 불러오기)
data['total_spent_normalized'] = scaler.fit_transform(data[['total_spent']])
# total_spent_normalized 컬럼에 total_spent 컬럼의 minmax 정규화 값 할당 해주기
# 결과 출력
print(data[['total_spent', 'total_spent_normalized']]) #두개의 컬럼 같이 출력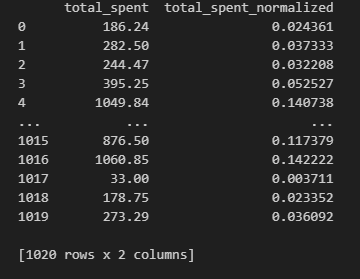
pandas.DataFrame.quantile — pandas 2.2.3 documentation
Include only float, int or boolean data. Changed in version 2.0.0: The default value of numeric_only is now False.
pandas.pydata.org
MinMaxScaler
Gallery examples: Release Highlights for scikit-learn 0.24 Image denoising using kernel PCA Time-related feature engineering Recursive feature elimination Univariate Feature Selection Scalable lear...
scikit-learn.org
'PYTHON' 카테고리의 다른 글
| 데이터 시각화 | Matplotlib 기본 그래프 ( bar / hist / pie / boxplot / scatter ) (0) | 2024.12.20 |
|---|---|
| 데이터 시각화 | Matplotlib 기본 of 기본 문법 (2) | 2024.12.19 |
| 코테 준비 | 프로그래머스 하샤드 수 / 두 정수 사이의 합 (리스트 컴프리헨션 & range) (0) | 2024.12.18 |
| 데이터 전처리 | Pandas 기본 함수 3 (concat,merge,groupby,pivot_table,sort_value) (1) | 2024.12.17 |
| 데이터 전처리| Pandas 기본 함수2 (loc, iloc,isin) (0) | 2024.12.17 |