1. SQL 실전 문제풀이 ( Lv3. 이용자의 포인트 조회하기 )
- 문제 : 전체 유저 ID별 토탈 포인트 출력 (user_id, email, point 컬럼)
( 단, 포인트 획득 내역이 없는 유저의 포인트값은 0으로 처리, 포인트 내림차순 정렬)
- 포인트 : 두 테이블 조인 방식 확인 & NULL 값 0 으로 치환
TABLE 1. users
: user 테이블은 스파르타 코딩클럽에 가입한 유저들의 정보를 날짜별로 기록한 테이블.
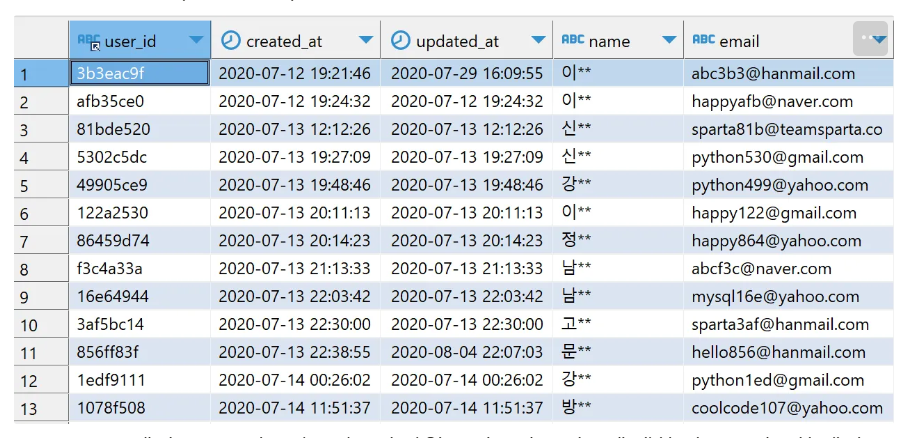
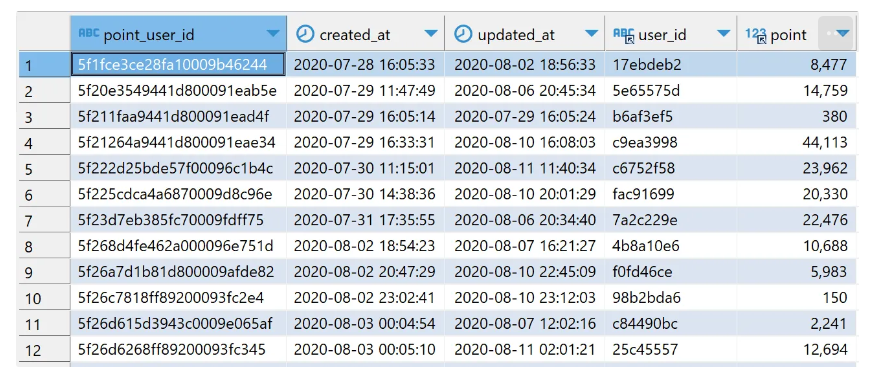
TABLE 2. point_ users
: point_ users 테이블은 스파르타코딩클럽 가입 유저들의 포인트에 대한 정보를 기록한 테이블.
- 풀이 과정 (문제풀이 & 피드백)
1. 문제풀이
- 집계 : point_users 테이블에서 user_id 별 토탈 포인트 집계 후 서브쿼리 생성
SELECT user_id
,SUM(point) AS total_points
FROM point_users
GROUP BY user_id- join : 두 테이블의 조인키 user_id로 조인 & 문제에서 전체 유저 출력이므로 Left join 선택
- null 처리 : users 테이블에만 있는 user_id의 point 값은 null 로 저장 됨.→ NULL 값 일때 다른 값으로 변환해주는 IFNULL 함수 사용하여 NULL 값 0으로 변경
- 정렬 조건 : point 컬럼 기준 내림차순
WITH points AS( -- 유저별 전체 포인트 테이블 서브쿼리, WITH문으로 가독성 높임
SELECT user_id
,SUM(point) AS total_points
FROM point_users
GROUP BY user_id
)
SELECT u.user_id
,u.email
,IFNULL(p.total_points,0) AS point -- total_points 컬럼의 null값 0 처리
FROM users u
LEFT JOIN points p ON u.user_id=p.user_id -- 전체 유저 출력 조건 만족
ORDER BY 3 DESC -- 포인트 컬럼 기준 내림차순
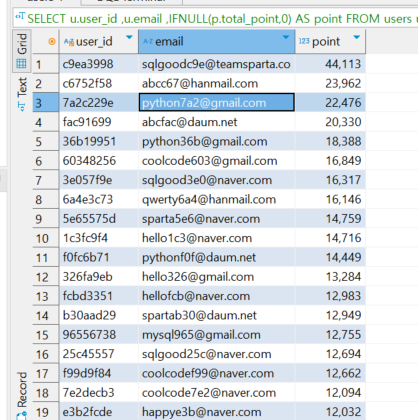
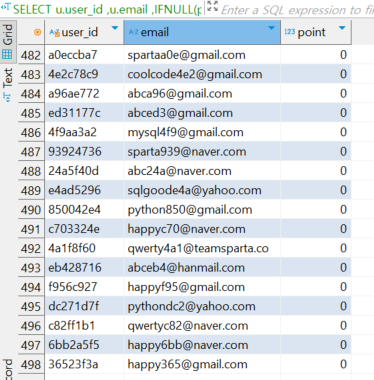
2. 정답 쿼리 및 피드백
- 정답 쿼리
SELECT
u.user_id, u.email,
COALESCE(p.point,0) as point
FROM
users u
left JOIN
point_users p ON u.user_id = p.user_id
order by p.point desc;- 피드백 사항
- EDA 미비로 인한 시간 낭비/오버 쿼리문 생성 : point_user 테이블에서 유저id 당 point 값은 1:1 로 저장되으며 중복 없는 테이블임 → 포인트 테이블의 경우, 유저 아이디별 포인트가 누적 되어 쌓일 것이라고 추측하여 아이디당 포인트 집계 후 with 문으로 서브쿼리 만들었음
- Insight : 테이블 EDA는 충분히 선행 되어야 함. (시간낭비 할수 있음)
SELECT user_id
,COUNT(point) -- user_id별 point는 1개만 저장 된다
FROM point_users pu
GROUP BY user_id
ORDER BY 2 DESC🔥NULL 값 처리 함수 ( IFNULL / COALESCE + ISNULL)🔥
1. IFNULL ( A, B ) : A가 NULL 이면 B 반환
- NULL 일때 값 변경
- 비 표준 함수로 MYSQL만 지원 (단일 값 확인)
- IFNULL(x, y) = (CASE WHEN x IS NULL THEN y ELSE x END)
2. COALESCE ( A ,B · · · ) : A 가 NULL 이면 B 출력 ,아니면 A 반환
- NULL 일때 값 변경
- 표준 함수로 여러 DB에서 사용 가능 (다중 값 확인)
- COALESCE(x, y, z ) = (CASE WHEN x IS NOT NULL THEN x
- WHEN y IS NOT NULL THEN y
- ELSE z END)
3. ISNULL( A ) : A가 NULL 이면 1 아니면 0 반환
- NULL 여부 확인
- ISNULL(x) = ( CASE WHEN x IS NULL THEN 1 ELSE 0 END)
4. MYSQL 에서 단일컬럼 NULL 치환 시 IFNULL 다중 치환시 COALESCE 사용 가능
그 외 DB 에서는 COALESCE 로 NULL 값 치환 가능
2. SQL 실전 문제풀이 ( Lv4. 가장 높은 월급을 받는 직원 구하기)
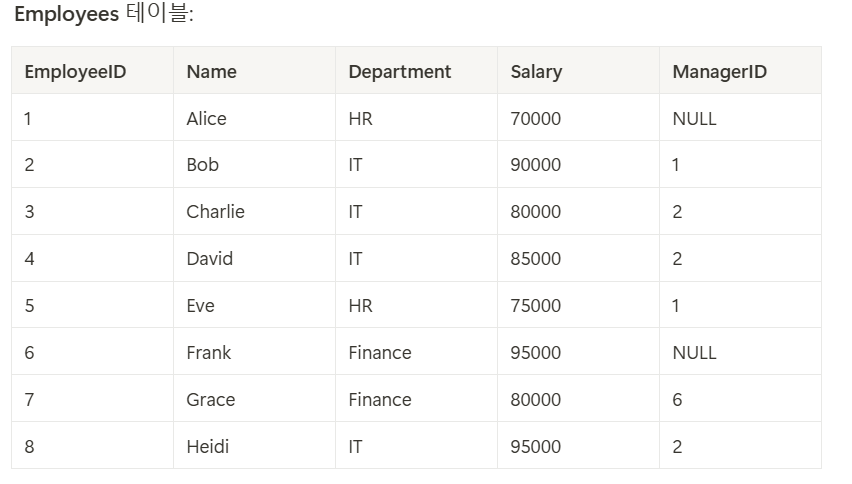
문제1 : 각 직원의 이름/부서/월급과 그 직원이 속한 부서에서 가장 높은 월급을 받는 직원 이름과 월급 조회하기
▶ 포인트. 그룹바이 전 행 값 & 그룹바이 후 집계 값 같이 출력 → 조인 활용
테이블
기대결과
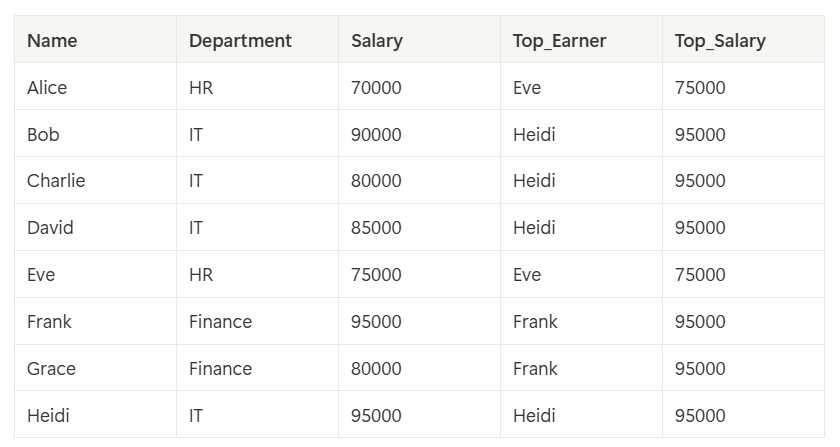
- 풀이 과정 (문제 풀이 & 피드백)
1. 문제풀이
- 윈도우 함수 사용하여 기존 테이블과 그룹핑한 집계값 함께 출력
- <오류> 부서별 가장 높은 월급을 받는 직원 이름 : MAX (직원명) OVER (PARTITION BY 부서 ORDER BY 월급 DESC )= 부서별 월급이 높은 순으로 정렬 된 상태에서 이름이 사전순으로 가장 큰 값 출력
- 부서별 가장 높은 월급 : MAX (월급) OVER (PARTITION BY 부서)= 부서별 가장 높은 월급 출력
-- #1 문제풀이 (오류 있음)
SELECT Name
,Department
,Salary
,MAX(Name) OVER (PARTITION BY Department ORDER BY Salary DESC) AS Top_Earner -- 오류
,MAX(Salary) OVER (PARTITION BY Department) AS Top_Salary
FROM Employees
2. 오류 사항
- Top_earner 컬럼 max() window 함수 동작 오류
- MAX(name) window 함수 사용시, 사전순 가장 큰 이름 출력하는 하게 됨.
- partition by / order by 조건하에 그룹핑 & 정렬하더라도 max의 파라미터가 string 이기 때문에 사전순 가장 큰 이름을 반환하게 됨.
- 부서별 최고 월급자의 이름을 반환하는 게 아니다!
3. 해결 & 쿼리 수정
- 순번 매기기 윈도우 함수 & 조인 : 부서별 가장 높은 월급 순으로 넘버링 해준 후 서브쿼리 감싸서 필터링 해줌 최종적으로 최고 월급자 테이블 조인 하여 출력 함
- 동일 월급자 있을 경우, 1명 만 출력 : ROW_NUMBER() OVER (PARTITION BY Department ORDER BY Salary DESC)
- 동일 월급자 있을 경우, 전부 만 출력 : RANK() OVER (PARTITION BY Department ORDER BY Salary DESC) --dense_rank 도 가능
TIL | JOIN/ GROUP BY/ 서브쿼리/ 순번 지정 윈도우 함수
📂SQL 실전 문제풀이 (LV4. 단골 고객 찾기)문제1 : 고객별 주문 건수와 총 주문 금액 조회 하기 (주문 안한 고객도 포함) ▶ POINT. 그룹바이 하고 집계 & 테이블 조인후 매칭 컬럼 출력 [테이
cookievlog.tistory.com
-- 수정 쿼리
WITH rk_t AS ( -- 부서별 월급 높은 순서로 순번 매기기
SELECT *
,ROW_NUMBER() OVER (PARTITION BY Department ORDER BY Salary DESC) AS rk
FROM Employees
), top AS ( -- 부서별 최고 월급자 필터링
SELECT *
FROM rk_t
WHERE rk=1
)
SELECT e.Name -- 사원테이블에 최고 월급자 테이블 조인
,e.department
,e.Salary
,t.Name AS Top_Earner
,t.Salary AS Top_Salary
FROM Employees e
INNER JOIN top t ON e.Department=t.Department
4. 정답 쿼리
- 최고 월급 correalated 서브쿼리로 필터링 & 조인 연결하여 문제 컬럼 출력
SELECT
e1.Name,
e1.Department,
e1.Salary,
e2.Name AS Top_Earner,
e2.Salary AS Top_Salary
FROM
Employees e1
JOIN
Employees e2 ON e1.Department = e2.Department
WHERE
e2.Salary = ( -- 최고 월급 필터링, correlated 서브쿼리로 아우터 쿼리 연결
SELECT MAX(Salary)
FROM Employees e3
WHERE e3.Department = e1.Department
);
5. 피드백 & 인사이트
- 집계함수 window function 사용시, 윈도우 파라미터의 조건은 그룹핑 &정렬에 대한 조건. 최종 출력해주는 집계 기준으로 생각해야 함.
- 그룹핑 이전 테이블의 row 값과 + 그룹핑 후 값을 같이 출력할때 → 가공한(그룹핑) 테이블 조인 or 연관 서브쿼리 & 조인 해야함.
문제2 : 부서별로 평균 월급이 가장 높은 부서의 이름과 해당 부서의 평균 월급을 조회 하기.
▶ 포인트. 그룹바이 후 집계값 조회
- 풀이 과정 (문제 풀이 & 피드백)
1. 문제풀이
- 부서별 평균 연봉 & 평균 값이 가장 큰 순으로 정렬
- 가장 높은 평균 월급을 가진 부서 1개를 반환.
SELECT Department
,AVG(Salary) as Avg_salary -- 부서별 평균 연봉
FROM Employees
GROUP BY department --부서별 그룹핑
ORDER BY Avg_salary DESC -- 평균 월급 높은순으로 정렬
LIMIT 1 -- 평균 연봉 가장 높은 1개의 부서 출력
2. 정답 쿼리
- 서브쿼리로 부서별 평균 월급이 가장 큰 부서 필터링 해줌.
SELECT
Department,
AVG(Salary) AS Avg_Salary
FROM
Employees
GROUP BY
Department
HAVING
AVG(Salary) = (
SELECT MAX(Avg_Salary)
FROM
(SELECT AVG(Salary) AS Avg_Salary
FROM Employees
GROUP BY Department) AS subquery
)
3. 피드백 & 인사이트
- LIMIT 사용시, 동일한 최고 월급을 가진 부서가 2개 이상일때 임의로 1개만 출력 됨. (즉, 동률 일 경우 모든 부서가 출력되지 않는 한계점이 있음)
- 서브쿼리를 사용하여 최고 월급 부서를 전부 출력할 수 있음.
'SQL' 카테고리의 다른 글
| 실습 | 다중 컬럼 서브쿼리/ Correlated 서브쿼리/ DBeaver 에서 with문 사용 안될 때 해결 법 (0) | 2024.11.21 |
|---|---|
| 실습 | EDA / 다중 테이블 JOIN / 서브쿼리 VS 윈도우 함수 (1) | 2024.11.20 |
| 실습 | JOIN/ GROUP BY/ 서브쿼리/ 순번 지정 윈도우 함수 (0) | 2024.11.18 |
| 실습 | EDA / 특정 문자 필터링 / 날짜별 평균 값 구하기 (1) | 2024.11.15 |
| SQLD | 그룹 함수와 계층형 질의 (0) | 2024.11.14 |